einat-ebpf,用 eBPF 从头写一个 Full Cone NAT
本文为关于 einat-ebpf 的系列文章第(三)章。
推荐阅读《理解 NAT 和 NAT 行为、类型》。
Full Cone NAT 即有 Endpoint-Independent Mapping 及 Endpoint-Independent Filtering 行为的 NAT。
题图
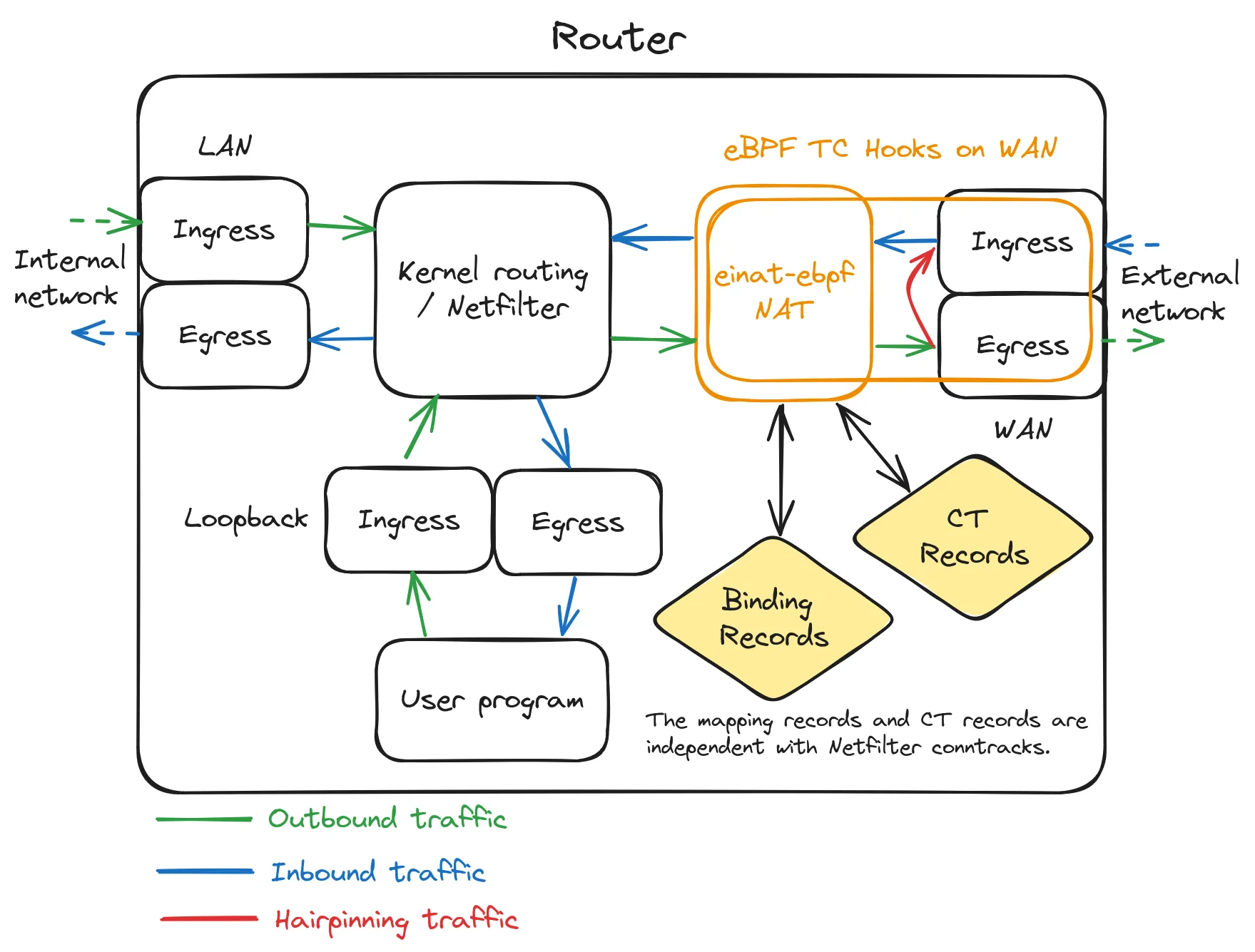
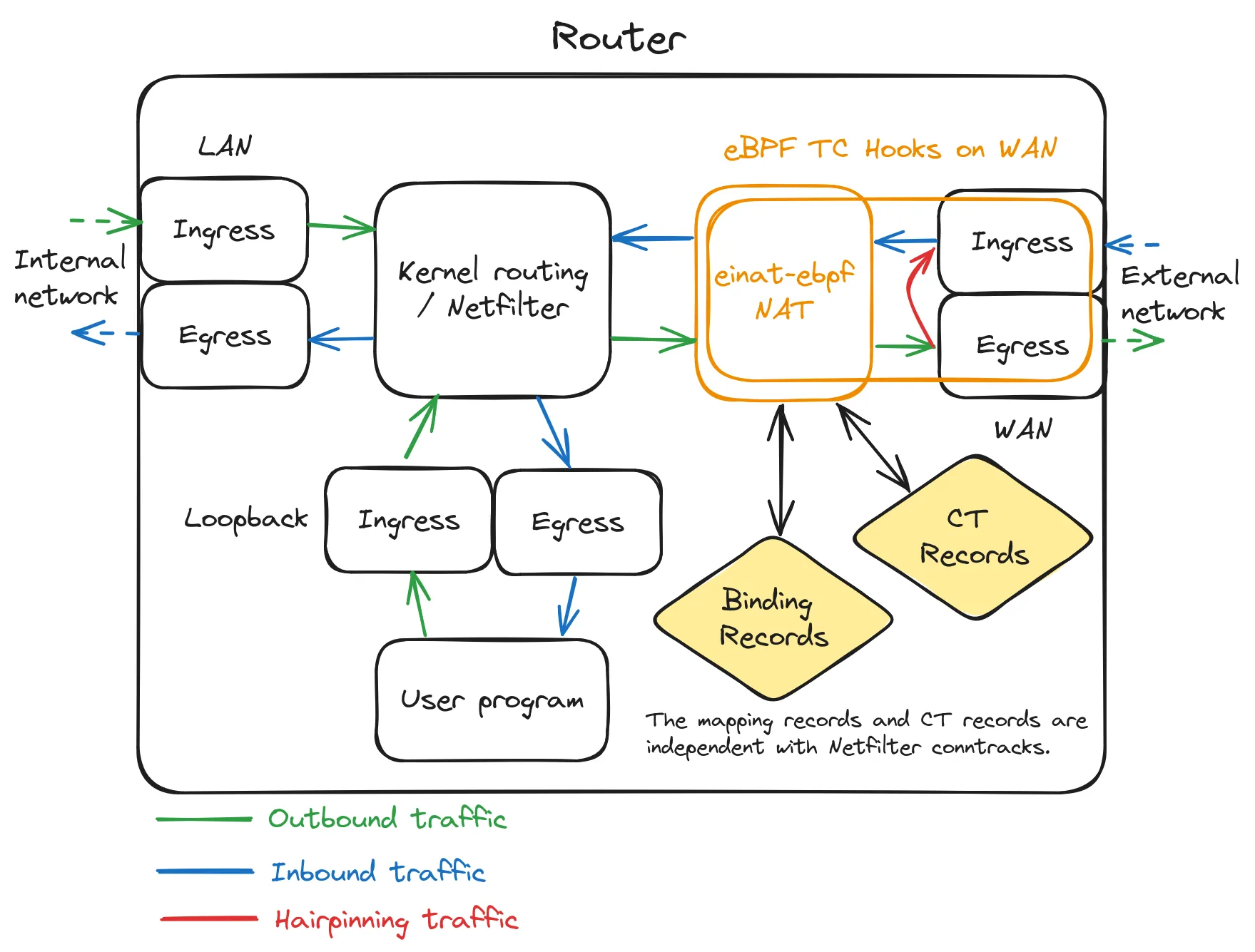
在一个典型 Linux 路由器中,einat 在 Linux 网络路由系统中的作用位置和经过 einat 的网络包流。
前言
此节从当前的公网端口开放需求和当前网络环境下的现有方案和问题出发,并最终给出了解决其中部分问题的 einat-ebpf 的开发动机。
前言较长,若你是网络高手或已经有一定程度的 NAT 相关理解可以跳到 einat 开发动机一节开始阅读。
公网端口
能在公网中打开一个端口是一个很常见的需求,不管是为了 P2P 应用如在 μTP 下工作的 BitTorrent、WebRTC、又或是隧道组网(Tailscale/NAT 穿透 + WireGuard), 还是为了 Tracker 模式下工作的 BitTorrent、监控服务、NAS 媒体服务、自建游戏服务器(如 Minecraft)等存粹打开一个无论是谁都可以从外部公网访问的端口。 对于不同的网络环境来说,通常有下面这些方案完成这些需求,其中适用于严格网络环境的方案一般也适用于更宽松的网络环境,并且我们不考虑除了 NAT 自身隐含的防火墙行为外的防火墙。
本机公网 IP
如果服务所在主机直接分配有公网 IP,如直接 PPPoE 拨号并可以获取到公网 IPv4 地址,这即是最宽松的网络环境,服务无需特殊操作就可打开公网端口。
路由器公网 IP + NAT
对于一般家庭网络来说,家中除 PC 外、还有手机、NAS、摄像头等一系列设备需要访问网络,而对于运营商只分配一个 IPv4 地址的当下,使用路由器进行 NAT 是必须的选择。 而如果这个 IPv4 地址幸运地是公网地址,那只需要在路由器上有 UPnP IGD、PCP 服务运行,大多数期望从外部访问的应用都支持利用这些服务打开端口并转发到本地服务端口。 而对于不支持利用这些服务的应用,也可以配置路由器将公网 IP 上的端口访问转发到内部主机的应用端口。
如在 Linux 路由器上利用 nftables DNAT 转发所有外部发起访问到特定的一个内部主机,此操作也可称为配置 DMZ 主机。
table inet nat {
chain prerouting {
type nat hook prerouting priority dstnat; policy accept;
dnat ip to 192.168.1.200
}
}
此外在某些运营商环境下,用户可以 PPPoE 多播获取多个不同 IP 地址,所以可以通过桥接外部网卡的方式使路由器和其后服务所在主机同时拥有公网 IP 地址, 以此拥有宽松的网络环境并保证不需要公网端口设备的网络访问需求。
运营商 Full Cone CGNAT
随着 IPv4 公网地址的枯竭,一般家庭用户只能分配到经过运营商 NAT(即 CGNAT)的私有 IPv4 地址, 但是所幸当今国内三大运营商 CGNAT 普遍配置了最透明的 Full Cone NAT(俗称 NAT1)策略。
对于在 Full Cone NAT 网络下的主机,只需要通过本地服务端口持续对外发起连接则 NAT 就会为其打开并维持外部公网地址的某端口,而外部地址和端口则可进而通过类似 STUN 的服务检测。
P2P 应用可以无缝地在 Full Cone NAT 下工作,而对于需要维持某端口打开的场景则可以利用 natmap 或 Natter 等在 Full Cone NAT 下工作的端口维持及本地转发应用。
其中在 BitTorrent DHT/PEX 网络下的表现是你可以观察到有
I 标志的传入连接的存在。
此外,若是运营商 CGNAT 同时提供了 PCP(Port Control Protocol)服务, 则可类似上“路由器公网 IP + NAT”的场景由应用主动请求打开公网 IPv4 端口并转发。
其他严格环境
对于其他网络环境,即不是 Full Cone(EIM + EIF)中蕴含的 EIF 的 NAT 网络环境,由于 NAT 过滤(即防火墙)策略的限制打开公开端口不再可能。
对于能够进行 P2P 打洞的应用,则还可以尝试与远端建立直接双向连接,特别是在 EIM 网络下(即使不是 EIF)。
而对于其他场景,用户只能通过如同 frp 等端口代理转发服务借用外部网络的公网 IP 地址并产生额外带宽而不能直接利用本地网络带宽。
现状与需求
现如今作为家庭宽带用户,大多都只能分配到 CGNAT 后的私网地址并与其他家宽用户共享公网 IP,而家宽用户个体则也有在家庭网络设备间共享外网访问的需求。 则运营商 CGNAT 加上本地路由器 NAT 的二级 NAT 是当下的普遍选择。
其中当今 CGNAT 普遍有最宽松的 Full Cone(EIM + EIF)NAT 行为, 而根据 NAT 行为的木桶原理可知, 二级 NAT 的 NAT 行为由可能更严格的本地路由器 NAT 决定。因此为了有更宽松的网络环境,我们希望本地的路由器也有同样最宽松的 Full Cone NAT 行为, 从而“运营商 Full Cone CGNAT”中提到内容可以同样适用。 而即使是有公网 IP 的网络,在路由器上配置动态 Full Cone NAT 也可以为所有内网主机提供更大的连通性从而有在打开端口方案方面的灵活性。
对于企业级路由器和部分有自有系统的消费级路由器来说,其原生地实现了动态“Full Cone NAT”并可选被启用,如华硕的路由器系统。 又或者是类似“公网 IP”场景使用桥接多播或配置端口转发静态地使少数的内网主机可以有 Full Cone NAT 行为。
而在如 OpenWrt 或其他发行版的 Linux 路由器(可归类为“软”路由)流行的当下, Linux 中事实上的标准动态 NAT 方案 Netfilter masquerade 和其基于的 conntrack 系统只支持有 EIM 特征的对称 NAT(APDM + APDF)行为, 而不拥有 EIF 过滤行为以允许打开端口上的任意传入连接1。
因此为了给 Linux 添加 Full Cone NAT 支持,前人想出了添加内核模块并利用现有 Netfilter NAT 和 conntrack 基础设施实现 Full Cone NAT 的方案2,
如 netfilter-full-cone-nat 及其启发的 nft-fullcone。
只要安装相应内核模块和 patch 过的 iptables/nftables 前端程序并在 prerouting 和 postrouting 的 DNAT 和 SNAT 阶段使用 fullcone NAT 操作替换 masquerade 操作即可为系统开启其实现的 UDP Full Cone NAT 支持。
IPV6
都 4202 年了,你怎么还在关心 NAT,直接换成 IPv6 啊!
要谈 NAT 特别是运营商 CGNAT 就绕不开通常也会分配的 IPv6 网段地址。 IPv6 对网络的连通性来说是巨大的提升。 但无论好还是不好,IPv4 仍是这个世界的默认语言,你可以不说 IPv6,但一定得说 IPv4。
并且,能免费获得的对 IPv4 网络连通性的提升,也是对 IPv6 网络很好的互补(It’s Free Real Estate!)。
einat 开发动机
我之前一直在使用上述 Netfilter 内核模块中的 nft-fullcone, 并维护和部署在我的 R2S 上的 NixOS 系统中。
然而由于这些模块是 out-of-tree 的即没有合并在内核代码中,
- 需要对每个内核版本分别构建相应内核模块
- 这些模块代码使用的内核 API 并不稳定所以存在构建失败或语义改变的风险
且这些模块依赖的前端程序 iptables 或 nftables 及其相应的库代码需要被 patch 以在 iptables 或 nftables 中添加 fullcone 的操作,
- 需要在升级 iptables 或 nftables 前端程序时应用 patch
- 由于相应 patch 没有更新或更新滞后可能不能应用旧的 patch 或存在使用的 API 语义改变的风险,实际上在我写 einat 之前就存在过前端程序补丁无法应用的情况。
并且这些内核模块和补丁都或多或少停止更新了,或者说并没有以一种为 Linux 通用的软件更新的形态发布, 比如 nft-fullcone 更新后的补丁只存在其作者的个人 openwrt 仓库中。 (nft-fullcone 组织中的仓库在我接近发布 einat v0.1.0 前归档了)
作为一个自己 Linux 路由器系统和相关包的维护者,我从中感受到了痛苦。 而作为一个开发者,在审视了这些基于 Netfilter conntrack 的 Full Cone NAT 实现后和此模型的缺陷后, 以及考虑维护该实现所需要的精力成本,我也无兴趣 fork 或新建一个版本自行维护。
einat 的初始版本仍然基于 Netfilter conntrack, 但事后我发现这是一个有缺陷且失败的实现,因此之后我依据相关 RFC 从底层开始实现了一个独立于 Netfilter conntrack 且完整的有 EIM + EIF 行为的 NAT。 本篇文章为避免混淆不将开发初始版本的经历列入叙事中。
此外经过网络上 eBPF 各种文章和应用的轰炸,我发现了一个新的可能性。TC eBPF 钩子允许 eBPF 程序对网卡上入口和出口的网络包进行修改过滤, 而且可以利用 eBPF maps 的全局存储来存储或读取端口映射表和连接跟踪表,这与最基础的 NAT 模型完美匹配。 而我们可以无需关心 Linux Netfilter 系统或网络栈实现而根据我们的意愿实现一个有 EIM + EIF 行为的 NAT。 并且实际上也早有 Cilium 在其 eBPF 网络中实现了有状态 NAT,虽然其是完全在网卡入口处工作并进行主动路由转发的。 而 eBPF 程序完全在用户态加载,且可以只利用 eBPF helpers 的稳定 API, 并且利用 libbpf 的 CO-RE 特性可以实现单次编译但跨内核版本的 eBPF 程序二进制码加载, 因此没有上述 Netfilter 内核模块和前端软件的维护负担。这就是 einat 项目的开始。
在这之上,由于 TC eBPF 程序可以直接接触网络包数据的灵活性,我们可以原生地实现对 TCP 连接状态的跟踪而不费力地实现对于 TCP 的 Full Cone NAT。 相比于未实现 TCP Full Cone NAT 的上述内核模块(要实现也不是很难,只是没人做),einat 可以为内网主机提供开放 TCP 外部端口的灵活性, 如允许内网主机而非仅在路由器上使用 natmap 或 Natter 开放 TCP 服务。
einat 介绍
只要把 einat 附在出口网卡上,除了配置排除的外部地址端口外,任何转发到该出口网卡的网络包都会被 einat 透明地执行 EIM 的 SNAT, 而任何进入网卡的网络包都会根据 EIF 进行过滤并透明地执行 EIM 的 DNAT 从而可以被 Linux 系统转发回初始源。 这相当于你的内网包直接转发出了出口网卡,但出口网卡外还有一个 Full Cone NAT 设备透明地为这些包执行 NAT 操作,并且使用的是出口网卡上的地址作为 NAT 外部源地址。 也因此 einat 对系统现有的 iptables/nftables 规则以及路由转发不会有影响(如果配置了 hairpinning 则可能对某些策略路由配置产生影响)。
# 为节省构建时间,下载为 x86_64 预构建的 einat
wget -O einat https://github.com/EHfive/einat-ebpf/releases/latest/download/einat-ipv6-static-x86_64-unknown-linux-musl
chmod +x einat
# 将 einat 附在 wan 网口上并开启可选的 hairpinning 路由
sudo ./einat -i wan --hairpin-if lo lan
在 eBPF 程序方面,einat 提供如下功能:
- 对 TCP、UDP、ICMP 的有 EIM + EIF 行为的 NAPT44 和 NAPT66
- 允许配置 NAT 使用的外部端口范围,使用户可以保留外部端口以供其他使用(如 NAT 主机自有外部服务)
- 对 ICMP 初始入站网络包的支持,允许 NAT 主机接收任意入站 ICMP query 包(如 ping 用到的 ICMP echo)
- 允许配置碎片跟踪记录和连接跟踪记录的超时时间(寿命)
- 对外部地址和目的地址配置是否进行 SNAT
- 对目的地址为外部地址的网络包进行 hairpinning 转发
而在配合 eBPF 程序工作的前端程序方面,einat 提供如下功能:
- 监测网卡的上线状态并动态附上(attach)或分离(detach)einat 的 TC eBPF 程序
- 监测网卡的地址变化并动态更新 eBPF 程序中相关配置
- 同样配置并动态更新 hairpinning 策略路由规则
具体使用说明见 einat-ebpf 的 README 和样本配置文件。
实验
为了测试 einat 的 NAT 行为,我们用 ip netns 配置与上一篇文章《Netfilter masquerade 的 NAT 行为到底是什么》实验中相同的网络拓扑结构, 只不过在路由器上不配置 Netfilter masquerade 而是使用 einat。以下 shell 命令均默认在 root 权限下运行。
netns 配置示例
#!/usr/bin/env bash
set -eux
ip netns add server1
ip netns add router
ip netns add device1
## add interfaces
ip link add br-lan netns router type bridge
ip link add wan netns router type veth peer veth_s1_r netns server1
ip link add lan1 netns router type veth peer veth_d1_r netns device1
## setup server network
ip netns exec server1 ip addr add 10.0.1.1/24 dev veth_s1_r
ip netns exec server1 ip addr add 10.123.123.100/24 dev veth_s1_r
ip netns exec server1 ip addr add 10.123.123.200/24 dev veth_s1_r
ip netns exec server1 ip link set veth_s1_r up
## setup router external network
ip netns exec router ip addr add 10.0.1.100/24 dev wan
ip netns exec router ip link set wan up
ip netns exec router ip route add default via 10.0.1.1 dev wan
## setup router internal network
ip netns exec router ip link set lan1 master br-lan
ip netns exec router ip addr add 192.168.1.1/24 dev br-lan
ip netns exec router ip link set br-lan up
ip netns exec router ip link set lan1 up
## setup device network
ip netns exec device1 ip addr add 192.168.1.100/24 dev veth_d1_r
ip netns exec device1 ip addr add 192.168.1.200/24 dev veth_d1_r
ip netns exec device1 ip link set veth_d1_r up
ip netns exec device1 ip route add default via 192.168.1.1 dev veth_d1_r
## enable IP forwading on router
ip netns exec router sysctl net.ipv4.ip_forward=1
## router: show networking info
ip netns exec router ip addr show
ip netns exec router ip route show
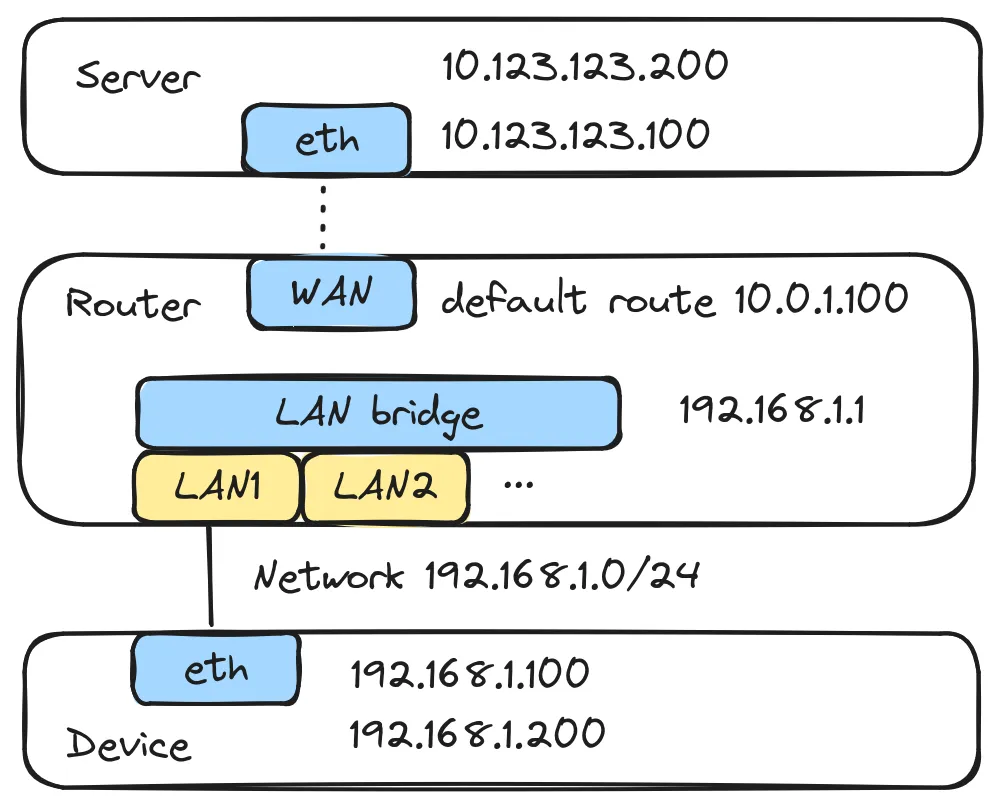
在路由器上保持运行 einat:
$ ip netns exec router \
./einat -i wan --hairpin-if lo br-lan
在服务器分别以 TCP 和 UDP 模式启动 STUN 服务,并在设备上分别测试对于 TCP 和 UDP 的 NAT 行为:
# 分别在后台运行 TCP 和 UDP STUN 服务
$ ip netns exec server1 \
stunserver --mode full --primaryinterface 10.123.123.100 \
--altinterface 10.123.123.200 --protocol tcp
$ ip netns exec server1 \
stunserver --mode full --primaryinterface 10.123.123.100 \
--altinterface 10.123.123.200
# 另起一个 shell
$ ip netns exec device1 \
stunclient --mode full --localport 29999 10.123.123.100 \
--protocol tcp
# TCP NAT 行为测试结果为 EIM
Binding test: success
Local address: 192.168.1.100:29999
Mapped address: 10.0.1.100:29999
Behavior test: success
Nat behavior: Endpoint Independent Mapping
$ ip netns exec device1 \
stunclient --mode full --localport 29999 10.123.123.100
# UDP NAT 行为测试结果为 EIM + EIF
Binding test: success
Local address: 192.168.1.100:29999
Mapped address: 10.0.1.100:29999
Behavior test: success
Nat behavior: Endpoint Independent Mapping
Filtering test: success
Nat filtering: Endpoint Independent Filtering
可以看到成功检测出了对 UDP 的 EIM + EIF 即 Full Cone 的 NAT 行为。 其中的 TCP NAT 过滤行为由于 Linux TCP 协议栈默认不允许监听模式的端口主动向客户端发起连接,因此该 STUN 实现无法测试对 TCP 的 NAT 过滤行为, 不过理论上是可以实现的。 这里 einat 对于 TCP 的过滤行为也是 EIF 的,具体可以利用 natmap 或 Natter 开放 TCP 服务并通过外部访问进行验证, 见 einat 用例。
工作原理
关于 einat 的 NAT 及 EIM + EIF 的 NAT 行为的实现原理遵循 《理解 NAT 和 NAT 行为、类型》,这里不再赘述。 这里仅对 einat 在 eBPF 下的其他实现细节进行讲解。另见 einat-ebpf 项目中的参考文档。
NAT 模型
如题图所示,einat eBPF 程序挂附在网卡的出口(egress)和入口(ingress)TC 钩子上。 在出口处网络包实际发出到网卡前,einat 的 egress 钩子程序对网络包进行 SNAT 并查询及实时更新映射规则表和连接跟踪表。 而在入口处接收网络包后并在发送至内核网络系统前,einat 的 ingress 钩子程序查询及实时更新映射规则表和连接跟踪表并根据查询结果进行 DNAT。
einat 的预想场景是只挂附在出口网卡上,而网络包的路由仍旧由 Linux 路由系统进行。 而通常的 eBPF 网络方案如 Cilium 的 NAT 则是在仅在网卡入口(ingress)工作,因此还需要挂附所有入口网卡的 ingress 钩子进行 SNAT 操作, 并且还可能主动进行路由转发从而绕过 Linux 网络系统。 而 einat 的当前 NAT 模型因为仍经过传统的 Linux 网络包路径,所以允许 Netfilter 对 NAT 前网络包进行过滤 (也因此没有转发的软 offload,但你仍可使用 nftables flow offload)。
NAT 状态
einat 的 NAT 状态有映射规则表和连接跟踪表, 它们以 eBPF maps 中的哈希表 BPF_MAP_TYPE_HASH 形式分别存储。
每条映射规则记录内部源地址、端口和外部地址、端口的映射关系,在 einat 中我们分别以内部源和外部源作为索引将映射规则存入哈希表中,以在出口和入口处的可以进行直接检索。
而连接跟踪除了记录原始的内部源地址、端口和目的地址、端口,还记录外部地址、端口,即同时记录了内部视角的连接信息和外部视角的连接信息,也因此每条连接跟踪对应于一条映射规则。
连接跟踪存在超时时间,在 einat 中我们使用 bpf_timer 为连接跟踪设置计时器并在超时回调中删除对应连接跟踪记录。
在 einat 实现中,多条连接跟踪记录对应于一条映射规则,而当所有连接跟踪超时后映射规则由于没有被“使用”所以也失效,
因此我们在映射规则记录上存储 ref 引用计数对应的连接跟踪判断映射规则是否失效。所以在连接跟踪的超时回调中,若相应映射规则失效(ref=0)则同时删除此映射规则。
然而这里存在一个问题,eBPF 中缺少除 atomic 外的全局同步机制(有对于单个 eBPF map 条目的 spinlock 机制,这里不讨论),而 eBPF 钩子程序可能被并行运行,
因此映射规则和对应连接跟踪的引用关系无法被保证,因为 eBPF maps 的条目可以任意被覆盖删除。
为了缓解这个问题,我们为映射规则引入了唯一序列号(seq)并仅在新建映射规则时赋予,并且在新建连接跟踪时继承对应映射规则的序列号。
所以当比对映射规则的和连接跟踪的序列号不一致时,则映射条目一定被覆盖了所以当前连接跟踪失效。当前的 einat 实现对失效的连接跟踪直接删除并丢弃处理中的包以确保全局引用状态的一致。
IP 分片
在 eBPF 中,由于无法进行动态内存分配(memory allocation),因此无法实现 IP 分片合并或重新分片。
在 IP 分片的包序列中只有序列中的第一个包存在记录端口信息的传输层 TCP、UDP、ICMP 的包首。 而在 NAPT 中端口信息是索引映射规则所必要的,故为了对不存在端口信息的序列中后续 IP 分片包进行映射, 我们需要对 IP 分片序列的标识符(IP ID)进行跟踪以可以索引 IP 分片序列的端口信息。
但也应 einat 只进行了简单的分片跟踪, 如果接收到的 IP 分片是乱序的且分片序列中的首个分片包不是最先被跟踪的, 则之前的分片包由于没有端口信息无法被正确映射,从而只能被丢弃而造成丢包的表现。 对于当今网络环境较稳定且 IP 分片不再推荐被使用3的形势下,此问题影响不大。
Hairpinning
Hairpinning 即允许 NAT 内主机间通过 NAT 外部地址互相访问,具体的说, NAT 内主机允许向其他目的 NAT 内主机的外部地址、端口发送包并允许接收源自其他目的 NAT 主机的外部地址、端口的包。
在 einat eBPF 出口处,若是当前网络包的目的地址是(网卡的)外部地址, 则 einat 会将此包进行 SNAT 并重定向到相同网卡的入口处再进行 DNAT,进而返回 Linux 路由转发到对应目的内部主机, 而内部主机则可依据此经过 SNAT 的外部源地址进行回应。
然而 Linux 默认将网卡的外部地址视为本机地址,并在 local 路由表中添加条目将以外部地址为目的地址的包进行本机路由,因此上述的路由路径无法经过。
为了将 hairpinning 的包路由到出口网卡使 einat 可以进行 SNAT 和重定向和 DNAT,
einat 的前端程序会修改并添加策略路由规则使目的地址为网卡外部地址的包路由到挂附的网卡,且策略路由规则仅匹配非挂附网卡的入口网卡以防止网络包的无限循环。
其中如果目的端口是排除 NAT 的外部端口则网络包会继续路由回本机。
前端程序
这里的“前端”显然不是指“Web 前端”,而是指与 eBPF 程序配套的在用户态工作的面向操作用户的前端程序。
einat 的用户空间前端程序使用 rtnetlink 监测网卡状态和网卡地址变化并动态更新 einat eBPF 程序中的地址相关配置。 并且当某地址被删除后,einat 前端程序会遍历状态表并将相关的映射规则和连接追踪从中删除以防止失效地址的映射规则无限地被刷新而导致网络断开。
开发痛点
eBPF Verifier
eBPF 程序需要被 eBPF Verifier 对所有分支进行模糊测试以确保内存安全及符合其他限制。 而 eBPF Verifier 对于最多能测试的分支指令有 100 万的上限,且分支越多验证时间越长。 einat 的一个预想工作目标是性能较低的路由器,因此优化验证性能是我的一个开发目标, 实际上目前 einat 仅在 NAT44 模式下工作在 R2S 下也需要 600 多毫妙进行验证。 在开发 einat 过程中我总结出了如下部分经验。
对于分支变量,其下的分支数量取决于变量的可能值的数量,因此对于变量需要尽可能的做边界检测尽早退出分支以限定分支数。 而如果可能则使用常数或立即数使分支数量只为 1。
在部分情况下,由于编译器优化,
变量可能会因为被优化入引用语句中导致边界检测代码被优化掉或无法被 eBPF Verifier 确认等从而增加验证分支数量,
因此需要使用内存屏障 barrier_var 防止优化。
eBPF 数据结构
eBPF 程序限制 512 比特的栈,虽然一定程度上可以使用 eBPF per-cpu map 缓解。
为了减少栈深度的扩张需要尽可能的限制栈变量的作用边界,以尽早回收栈空间,比如将代码块围上 { } 或使用 inline 函数封装功能。
eBPF 程序中不能直接通过指针构建引用的数据结构(有新 API 允许构建队列、树等数据结构,但是不支持直接索引查询), 这使得我们不能使用多级索引的数据结构,也限制了能在 eBPF 中实现的逻辑。 在 einat 中,我们因此无法实现在 EIM 上的非 EIF 的 ADF 和 ADPF 过滤行为(由于需要在映射规则上额外记录任意个外部目的地址或端口)。
前端程序
使用 tokei 统计 einat-ebpf v0.1.2 的代码行数,其中 C eBPF 共有 2027 行,而前端程序的 Rust 有 2788 行。 当然其中的开发时间与代码行数并不匹配,但也可以看出前端程序的开发和 eBPF 程序的开发相比也花费了不少的劳力。
由于 einat 需要根据网络地址信息进行工作, 而为了用户体验也不能让用户静态地去配置 einat 以反应可能动态变化的地址, 因此我花费时间为 einat 实现动态配置网络地址信息。
总结
在开发 einat-ebpf 的过程中我学到的很多,IP、TCP、UDP、ICMP、NAPT 等我之前都是知其然不知其所以然(大学计算机网络白上了), 而我也接触了之前一直想要了解的 eBPF 并意外了解了 Linux 的 netlink 接口、路由等方面。可以说我现在才理解了当前的计算机网络实现。
实现是理解的最佳途径,你会学习,而学到知识允许接触更多。
等等?可能 einat 并不必要
或者说你并不一定需要在 Full Cone CGNAT 后再级联一层本地 Full Cone NAT 路由器?
我们已经知道有 natmap 或 Natter 这样的工具允许在 Full Cone NAT 网络下维持端口打开并转发到目标服务端口。 而且将他们部署在有 Full Cone NAT 网络的路由器以暴露内部网络服务也是预想的使用场景。
而类似 miniupnpd 这样的在公网 IP 下工作的 UPnP IGD、PCP、NAT-PMP 端口映射服务也是类似部署在路由器上, 并根据客户端的请求使用 iptables/nftables 转发端口,只不过相比上工具无需额外端口维持操作。
那么,为何不在 natmap 或 Natter 的端口维持方法的基础上实现 UPnP IGD、PCP、NAT-PMP 服务端来接收端口映射请求呢? 这就是基于 STUN 的 UPnP IGD、PCP、NAT-PMP 端口映射服务4, 且是 miniupnpd 在 Full Cone NAT(甚至公网 IP)下的完美平替。
当今的 P2P 应用(WebRTC 除外)大多都支持 UPnP IGD、PCP、NAT-PMP 中的至少一样请求端口。 且对于一对一 P2P 应用(如 WebRTC、Tailscale)来说,只要有相应的打洞协议, Netfilter 所提供的类似 EIM 行为也足以使其可以双向连通,所以末端 Full Cone NAT(如 einat)提供的 EIF 也不是必要的。
而传统的内部主机的端口映射请求当然也可以直接使用支持这些协议的客户端软件达成。
因此在大多数场景下,上述所提的在 Full Cone NAT 网络下工作的基于 STUN 的端口映射服务加上有类似 EIM 行为的 Netfilter masquerade NAT 都可满足末端用户需求。